pandas なのか openpyxl がいいのか?
pythonでExcelやcsvファイルを扱うなら、「 pandas」だの「openpyxl」を使えだの出てくる。
初心だった私はまず二つあることに戸惑ったことを覚えている。これまた違いを解説したサイトは数多あるわけだが、正直情報過多なものばかりでイライラしながら情報収集していたのを覚えている。
私の話はこれくらいで早速ですが、両者の違いは以下の通り(たぶん)
■ pandas
- 既に情報が書き込まれているCSVファイルのデータを色々扱いたい時に便利
→列の操作、行の操作などまとめて同じ処理をする時に直感的に扱いやすい。
- numpyと相互に変換しやすく統計処理やデータサイエンスを扱う時に色々便利。
■ openpyxl
- 自由度が高くセル単位で色々な操作が出来る。
→複数タブを取り扱ったり、画像を張ったり、罫線や文字サイズなども個別に指定できる。
- 何かを処理した結果を書き込みながらファイルを作っていくような操作も出来る。
こんな感じでやりたい操作にどちらが向いているのかの問題で優劣はないと思います。
まぁ詳細は他のサイトを見れば良いと思うのでこれで終わりでも良いのですが、
とりあえず当時の私に向けて基本のファイルの読み書き操作
をサラッと書いてみようと思う。
こちらを眺めて頂ければ上で述べた違いもなんとなくわかるのではと思っている。
注)各モジュールはインストールしている前提での説明です。
pandas の超基本操作
冒頭に書いたように既に入力された内容を操作するのに適している。とりあえず操作例を見せるための 「Test.csv」ファイルをエクセルで作ってみた。そして私はjupyter notebookでコードを書いていますが、ipynbファイルと同じ階層にcsvファイルを置きました。
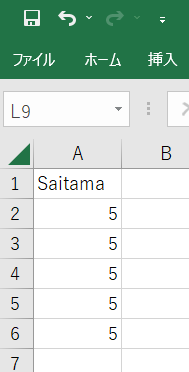
「Test.csv」の中身は、列名「Tokyo、Saitama、Chiba」 の3つが並んでいて、その下に数字が並んでいる超適当なファイルである。
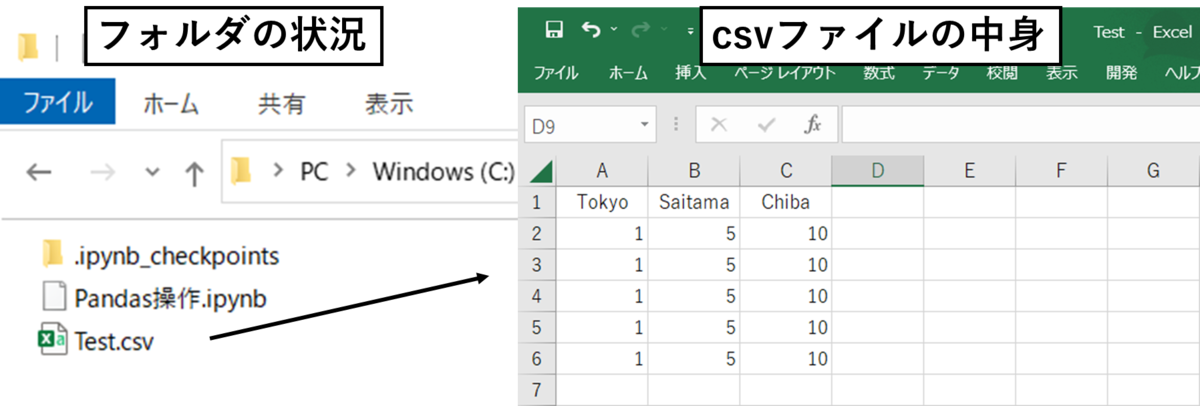
では、これをpython(pandas)で読み込んで表示してみる。
【コード】

・ 「pd.read_csv() 」でcsvを読み込みます。()に読み込むファイルを指定します。
⇒今回は同じ階層の Test.csv を読み込むため、「"./Test.csv"」を入れています。
・ ()内の「encoding = "shift-jis"」は必ずしも必要はないのですが、csvファイル内に日本語
とかがあると文字化けしてしまうため初めから入れておいて良いと思います。
なお、"shifi-jis" 以外に色々あるので調べてみてください。
・ 読み込んだ内容はデータフレームとして扱われます。ここでは変数「df1」に = で代入しています。
【表示されるもの】
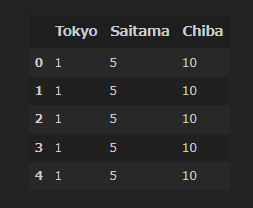
・ 少し上のcsvファイルの中身と比べてみてください。ほぼ同じですね。
・ 一番左に行番号が割り振られていますがデータに足されたわけではありません。
display( ) は操作が思い通りに出来たか確認するために重宝します。
続いて、簡単な操作を行ってみます。
【列名の抽出と操作】
csvファイルをデータフレームとして読み込みdf1に代入しました。
今から簡単な操作例として列名の抽出を行ってみます。

・ 抽出操作はデータフレームが入った変数の後に「.columns」を付けてできます。
・ 変数:colum_list に抽出した列のリストが格納されます。
(pythonのリストファイルそのものではないことは覚えておいてください。)
では、抽出した列名を使って2列目の"Saitama"だけ取り出してみます。
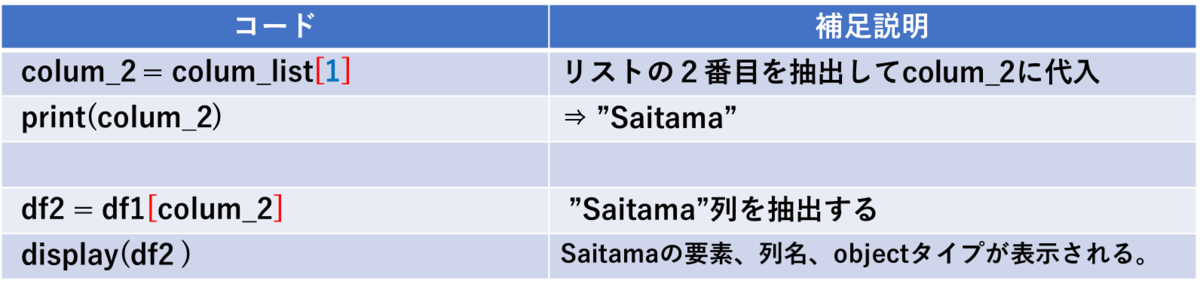
・ リスト操作の基本である [index番号] で2番目の要素”Saitama”を抜き出しています。
・ データフレームにおいても [カラム名] を使うことでその列を抜き出すことが出来ます。
・ displayでの表示内容は以下の左のようになります。

先ほど違って変わったように感じますが、列名が別途下に移っただけで実質的には右と同じです。
最後に、Saitama列を抜き出したdf2をcsvファイルへ出力してみます。
【csvファイルに出力】
コードは以下の通りになります。

・ 出力したいデータフレームの後ろに「 .to_csv() 」を付けることでcsvファイルが作成されます。
・ ( )内には、新しいファイル名と出力先を指定します。
・ 出力も同様に文字化け防止のため「encoding = "shift-jis"」を入れています。
フォルダには以下のように New.csv ファイルが出力されます。
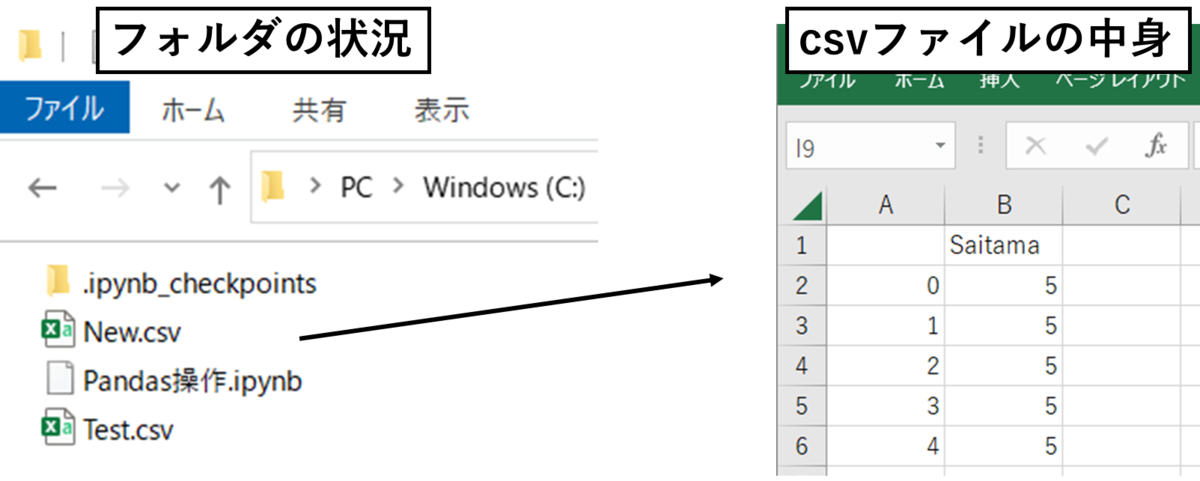
中身を見てアレって思ったと思います。そうです左側に余計な行番号の列が足されてしまいました。
これがいらない場合は、以下のように「index = False」を追加します。

このようにすることで行番号がない状態で出力が出来ます。
今回は列を操作しましたが、pandasでは行の操作もできます。列の抽出以外にも削除なんかもできます。あるいは列の要素を処理をすることも出来たりします。
他にも色々出来ますがまずは読み込みから書き込みの操作の基本をここで覚えましょう。
openpyxl の超基本操作
とにかく自由度が高いのがopenpyxlです。色々考えましたが、新規にワークブックを作りコメントを書き込んで保存する操作を例として説明します。
①ワークブックの新規作成

・ これはエクセルで言う空白のブックの新規作成に相当します。
⇓
②ワークシートの指定

・ この場合ワークシートは一つしかないので自明ですが、どのシート内を操作
するのかを自明にするために必要です。
・ シートの名前で指定することも可能です。
⇒ ws = wb["Sheet1"]
③セルへの記入
セルに記入するためにはセルを指定する必要があります。二つの指定方法があります。
■アドレスで指定する方法
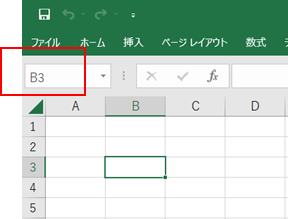
・ これはエクセルでなじみがあるのでわかりやすいかと思います。
・ 一方で、横軸がZを超えると複雑になっていく点やそれを指定する時に面倒くさい時があります。
ここでは上記のセルアドレスB3に、"Hatena" を書き込んでみます。

・ wbに [ ]を付けて、その中にアドレスを入れます。文字列であることを忘れないように。
・ 「 = @ 」で、@が指定したセルに書き込まれます。@は文字列でも数字でも構いません。
■セル番号(行列)で指定する方法

・ 一番左上のセルを(1, 1)として、(行番号 , 列番号) で指定する方法です。
・ 決まった間隔をあけて同じものを書くような場合は数字で扱った方がやりやすいです。
では、セルアドレスC3(セル番号では (3,3) )に "Blog" を書き込みます。

・ wsのcell(3,3)でC3が指定されたことになります。その後に「.value」 をつけることで
そのセルの値を意味します。
・ 先ほどと同様に「=」を使うことで書き込まれます。
指定方法はどちらでも大丈夫です。直感的にはセルアドレスの方が分かりやすいですが、セル番号の方が位置を数字で管理できることから便利な局面が多いためおススメします。
④エクセルファイルへ出力

・ wbの後に、「.save( )」を付けて、( ) 内に、ファイル名と保存先を指定します。
・ wsではなくwbであることに注意してください。
⑤ファイル内容の確認
New.csvをエクセルで開きます。

・ B3に”Hatena”、C3に”Blog” が書き込まれていますね。
コードまとめ
■pandas
import pandas as pd #ファイルの読み込み df1 = pd.read_csv( "./Test.csv" , encoding = "shift-jis" ) #内容を表示 display( df1 ) #df1のカラムのリストを抽出 colum_list = df1.columns #2番目のカラム名を抽出 colum_2 = colum_list[1] #df1から2番目の列だけ抜き出す。 df2 = df1[ colum_2 ] #抜き出したものをcsvファイルで出力。 df2.to_csv(" ./New.csv ", encoding ="shift-jis" , index = False)
■opnepyxl
import openpyxl #新規ワークブック(wb)の作成 wb = openpyxl.Workbook() #ワークシートの指定 ws = wb.worksheets[0] # ws = wb["sheet1"] でも良い。 #セルアドレスでワークシート(ws)へ書き込み ws["B3"] = "Hatena" #セル番号でワークシート(ws)へ書き込み ws.cell(3,3).value = "Blog" #ワークブック(wb)の保存 wb.save("./New.xlsx")
まとめ
簡単にといいながらなかなか長くなってしまいました。pandas はデータを整形する時に役立ちます。openpyxl は私達がマウスやキーボードを使ってエクセル操作する内容をコードで行えるといった感じです。自分がやりたい方がどちらかに合わせて選択すると良いと思います。